Beyond BERT
Introduction
This article talks about a few neural language models that were developed as improvements over the popular BERT model. The next section provides a short overview of BERT (Devlin et al.) but reading the original paper is recommended along with reading the ‘Attention is all you need’ paper (Vaswani et al.).
In this article, we discuss models that extend the capabilities of BERT by making it more accurate on tasks it was already good at, improving its performance on tasks it wasn’t very good at, and making it lighter and faster.
BERT
BERT is an encoder based on the transformer architecture. It stands for Bidirectional Encoder Representations from Transformers. In large part, BERT uses the original transformer architecture as is and benefits greatly from the self-attention mechanism that the transformer is based on. However, it makes some key changes including removing the decoder stack and introducing the Masked Language Modeling (MLM) pretraining task. Most of BERT’s predecessors were able to capture context in either a leftward or rightward direction. Attempts to make models bidirectional were limited to using a shallow concatenation of unidirectional contexts. The authors of BERT identified the masked language modeling task as an effective solution to making their model truly bidirectional. By masking tokens randomly and making BERT predict the masked tokens, BERT was able to capture bidirectional context and achieve new state-of-the-art results on benchmarks like GLUE and SQuAD among others. Another pretraining task used by BERT is the Next Sentence Prediction (NSP) task where, given a pair of sentences, the model must decide whether they occur consecutively in a document.

As shown in the image above, a pretrained BERT model can be easily adapted to most downstream tasks. The input begins with the special [CLS] token and can hold either a single or two sequences (separated by the special [SEP] token). The [CLS] token helps in sentence classification tasks because it is effectively a representation of the entire input.
Despite BERT having achieved the state-of-the-art on many tasks, it has flaws that researchers have identified and attempted to resolve. The following models are a few examples of such attempts.
RoBERTa
The authors of the paper that introduced RoBERTa (Robustly Optimized BERT Approach) claim that BERT was ‘undertrained’. They showed that with some basic changes to the model pretraining process, BERT could be greatly improved.
The changes proposed by the authors are:
- Train the model with bigger batches and more data
The original BERT was trained for 1M steps with a batch size of 256. This is equivalent in computational cost to training for 125K steps with a batch size of 2K, or for 31K steps with a batch size of 8K. To deal with the large batch size, the authors of RoBERTa used gradient accumulation which means that they would accumulate gradients over multiple batches and then update weights with an aggregation of those gradients. The authors also increase the amount of data that BERT was trained on by pretraining RoBERTa on ~160GB of additional data. - Removal of the Next Sentence Prediction pretraining task
The authors decided to get rid of the NSP task which had been proven to contribute very little to BERT’s performance. They packed each input with full sentences sampled contiguously from one or more documents, such that the total length was at most 512 tokens. - Dynamic masking
The original BERT used static masking which means that the tokens to be masked for the Masked Language Modeling pretraining task were fixed apriori. The authors of RoBERTa state that the drawback of this method is that only a fixed set of tokens will be masked and hence predicted every time. To combat this, they introduced dynamic masking in which they duplicated the training data with different masks in each copy.
When controlling for training data, the authors found that RoBERTa beat BERT on GLUE as well as SQuAD. Before RoBERTa, the efficacy of the MLM pretraining task had been thrown into doubt. However, RoBERTa cemented the fact that MLM is effective and at least as good if not better than other pretraining tasks.
BART
BART (Bidirectional and Auto-Regressive Transformers) is a denoising autoencoder that maps a corrupted document to the original document it was derived from. It was trained by corrupting documents and then optimizing a reconstruction loss — the cross-entropy between the decoder output and the original document. Unlike existing denoising autoencoders, which are tailored to specific noising schemes, BART allows us to apply any type of document corruption. In the extreme case, where all information about the source is lost, BART is equivalent to a language model.
In a sense, BART is the result of combining BERT and GPT. BERT is an encoder where random tokens are replaced with masks and the document is encoded bidirectionally. Since the masked tokens are predicted independent of each other, BERT does not perform very well on downstream text generation tasks. GPT on the other hand, predicts tokens auto-regressively. This means that each new prediction uses previously predicted tokens as context. This helps it perform very well on downstream text generation tasks. However, the downside of GPT is that since it only conditions on tokens in a single direction, it is not bidirectional.
The authors of the BART paper experimented with several data corruption schemes such as the following:
- Token masking: This is the MLM pretraining task made popular by BERT. Tokens are randomly replaced with a
<MASK>token and the model must predict these tokens. - Token deletion: Tokens are randomly deleted from the input and the model must predict the positions from which the tokens were deleted.
- Text infilling: Instead of single tokens being masked, spans of text are replaced with the
<MASK>token. The length of these spans is sampled from a Poisson distribution. Similar to MLM, the model must predict the text spans. - Document rotation: A token is chosen at random and the document is rotated so that it starts with that token. The model must predict the original start of the document.
- Sentence shuffling: Sentences are shuffled in random order. The model must predict the original ordering of the sentences.
- Text infilling + Sentence shuffling
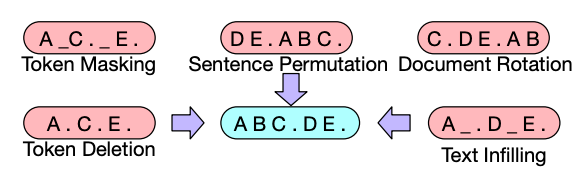
The authors found that using token infilling (along with sentence shuffling) resulted in BART performing extremely well on most tasks.
Since BART follows the encoder-decoder architecture, its usage for downstream tasks differs from BERT and the other models discussed in the article. For example, to use BART for classification tasks, the input is fed into both the encoder and the decoder and the final output of the decoder is used.
DistilBERT
As shown in the graph above, BERT-large has a whopping 340M parameters. While this allows it to hold a lot of information, it comes with a few drawbacks. It causes the model size to be incredibly large (>1GB) and to have a non-trivial inference time. This makes BERT impossible to run without dedicated machines and hence impossible to run on edge devices like smartphones.
The authors of the DistilBERT paper recognized this issue and proposed a version of BERT that they claim is 40% smaller and 60% faster while retaining 97% of BERT’s language understanding capabilities. To make the model smaller, they use a model compression technique called knowledge distillation.
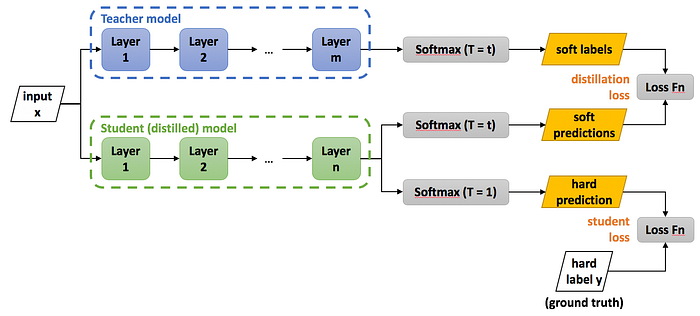
Knowledge distillation involves two models — the larger ‘teacher’ model (BERT in this case), and the smaller ‘student’ model (DistilBERT in this case). It allows us to ‘distill’ the information held in the teacher model’s (many) parameters into the (fewer) parameters of the student model. This is done according to the following steps:
Step 1: We are already in possession of the pretrained (and possibly finetuned) teacher model. Each training example is passed through this model and a softmax (with temperature t) is applied to each model output. We call these outputs the soft labels. They are termed as ‘soft’ because they represent a probability distribution rather than actual predictions.
(Note: a temperature is a value that every input is divided by before being fed into the softmax function. The purpose of applying a temperature to the softmax function is to make the outputs richer in information. The outputs provide more information about which classes the teacher model deems similar to the predicted class. This leads to an improvement in student model generalization.)
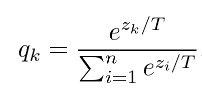
Step 2: Each training example is passed through the untrained student model and a softmax (with temperature t) is applied to each model output. We call these outputs the soft predictions. Parallelly, a softmax (with no temperature) is applied to each model output. We call these outputs the hard predictions. They are termed as ‘hard’ because we take an argmax over the softmax output to get actual predictions.
Step 3: We now calculate the distillation loss between the soft labels and the soft predictions. Since both of them are probability distributions we can use loss functions like cross-entropy or KL-divergence. We also calculate the student loss between the hard labels (the ground truth) and the hard predictions. Finally, we backpropagate on a (weighted) linear combination of these two losses to train the student model.
(Note: in practice, lower values of the temperature work better when the student model is very small relative to the teacher model, and the student loss should be weighted much smaller than the distillation loss in the final loss function)
In the case of DistilBERT, the student model is also a transformer-based architecture. It resembles BERT in most ways except that the token-type embeddings and the pooler are removed, and the number of layers is halved. The model is initialized by taking parameter values from every alternate layer in BERT. The final loss is a linear combination of the distillation loss and the MLM loss. DistilBERT also implements some of the changes made to BERT by the authors of RoBERTa like increasing the batch size (up to 4K) using gradient accumulation, removing the next sentence prediction pretraining task, and using dynamic masking.



In the first figure shown above DistilBERT’s GLUE score is nearly equivalent to that of BERT while eclipsing ELMo. In the second figure, we can see that DistilBERT’s performance on downstream tasks (IMDb -> classification, SQuAD -> QnA) is also almost equivalent to that of BERT. In the third figure, we can see that DistilBERT greatly reduces BERT’s parameter count and inference time.
Observations and Insights
- Each model discussed in this article incorporates learnings from its predecessor to improve its own performance.
- NLP’s recent rise to prominence has been in large part to breakthroughs in pre-training methods like next sentence prediction and masked language modeling.
- The majority of neural language models are extremely large and intractable. This acts as a bottleneck for adoption due to the large model size and prediction latency.
- Model compression techniques will play a big role in allowing these models to be used in a wider range of applications.
References
- Attention Is All You Need (https://arxiv.org/pdf/1706.03762.pdf)
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (https://arxiv.org/pdf/1810.04805.pdf)
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) (http://jalammar.github.io/illustrated-bert/)
- RoBERTa: A Robustly Optimized BERT Pretraining Approach (https://arxiv.org/pdf/1907.11692.pdf)
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (https://arxiv.org/pdf/1910.13461.pdf)
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter (https://arxiv.org/pdf/1910.01108.pdf)
- Distilling the Knowledge in a Neural Network (https://arxiv.org/pdf/1503.02531.pdf)
- Knowledge Distillation (https://intellabs.github.io/distiller/knowledge_distillation.html)
